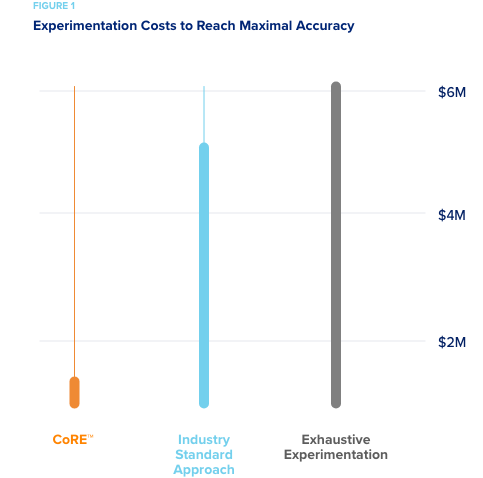
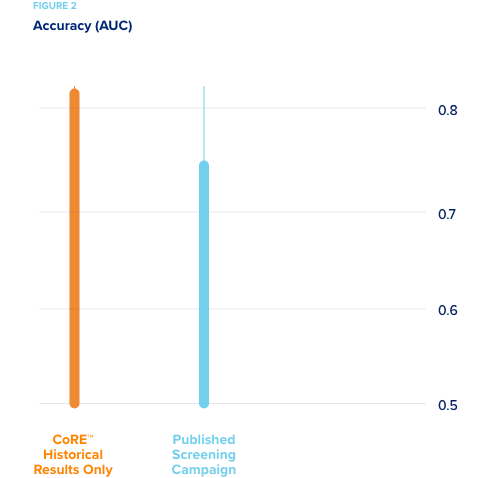
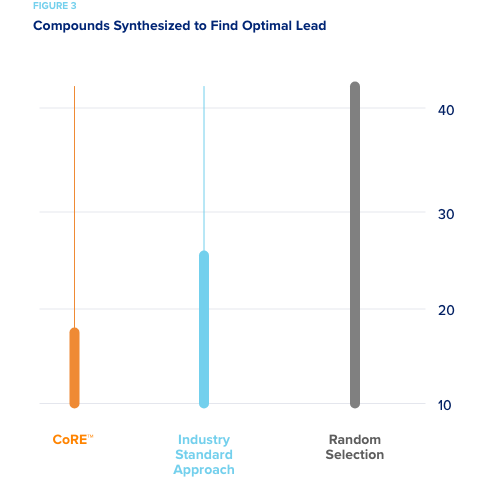


At SLAS Europe 2026, research powered by the Predictive Oncology biobank was featured in a scientific poster on integrated imaging and viability analysis of matched...Learn more

Drug repurposing using the Predictive Oncology machine learning approach and proprietary biobank of frozen dissociated tumor cells (DTCs) is outlined in this new white paper....Learn more

Drug repurposing using the Predictive Oncology machine learning approach and proprietary biobank of frozen dissociated tumor cells (DTCs) is outlined in this new white paper....Learn more


















